Understanding Session Windows in Flink: Concepts and ChallengesApache Flink session windows and challenges to keep in mind 🚀Jan 29Jan 29
From 1 to 100 000 Requests in Java: 4 Hour Journey Scaling using Netty and Virtual ThreadsSimplicity High Concurrency in JavaJan 31Jan 31
Building a Low-Cost Lakehouse for Near Real-Time Analytics with Apache Iceberg and Nessie CatalogA hands-on guide to leverage Apache Flink, Apache Iceberg, and Project Nessie for data processing in near Real-time with code and demo.Oct 14, 2024Oct 14, 2024
Boost Flink Deployment Efficiency on GCP with TerraformHands-on guide to learn how to deploy your Apache Flink Cluster on Google Cloud Platform using TerraformJul 8, 20241Jul 8, 20241
DaaS: Building a Low-Cost Lakehouse for Near Real-Time Analytics in Flink and HudiApache Flink, Hudi, and S3 can dramatically lower your analytics costs without compromising on data freshness or scalability.Apr 8, 2024Apr 8, 2024
Unlocking the Power of Flink with Kubernetes Operator: Simplify Data Management for DaaSGame-changer for simplifying data operationsJan 23, 2024Jan 23, 2024
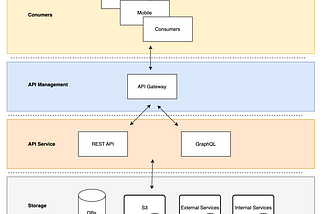
Enhancing Data as a Service with GraphQLData as a service using the power of GraphQL. Explore seamless data queries via API Gateway. Flexible, intuitive and efficient.Dec 22, 2023Dec 22, 2023
Data as a Service using ScyllaDBIn today’s data-driven world, efficient data management and accessibility are paramount. Data as a Service (DaaS) and the integration of an…Nov 22, 2023Nov 22, 2023
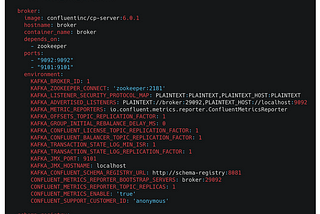
Don’t leave Apache Flink and Schema Registry aloneLearn how to add a schema registry in your architecture and bright with the simplicity and the advantages you add in your companyJun 3, 2021Jun 3, 2021
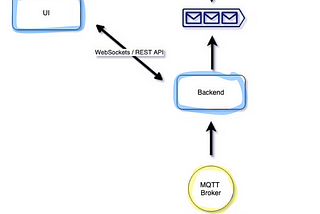
A simple way to build your Real-Time dashboardBuilding a live dashboard could be a headache due to the complex architecture and hard maintenance. Nowadays, the data is power and as…Jun 10, 20201Jun 10, 20201